
1·
2 days agoOk, I have to know: how is this done, and what do people use it for?
Ok, I have to know: how is this done, and what do people use it for?
For my own networks, I’ve been using IPv6 subnets for years now, and have NAT64 translation for when they need to access Legacy IP (aka IPv4) resources on the public Internet.
Between your two options, I’m more inclined to recommend the second solution, because although it requires renumbering existing containers to the new subnet, you would still have one subnet for all your containers, but it’s bigger now. Whereas the first solution would either: A) preclude containers on the first bridge from directly talking to containers on the second bridge, or B) you would have to enable some sort of awful NAT44 translation to make the two work together.
So if IPv6 and its massive, essentially-unlimited ULA subnets are not an option, then I’d still go with the second solution, which is a bigger-but-still-singular subnet.
For a link of 5.5 km and with clear LoS, I would reach for 802.11 WiFi, since the range of 802.11ah HaLow wouldn’t necessarily be needed. For reference, many WISPs use Ubiquiti 5 GHz point-to-point APs for their backhaul links for much further distances.
The question would be what your RF link conditions look like, whether 5 GHz is clear in your environment, and what sort of worst-case bandwidth you can accept. With a clear Fresnel zone, you could probably be pushing something like 50 Mbps symmetrical, if properly aimed and configured.
Ubiquiti’s website has a neat tool for roughly calculating terrain and RF losses.
I don’t have an answer for your woes, but MTU issues are notoriously difficult to investigate and mitigate, as Cloudflare found out: https://blog.cloudflare.com/increasing-ipv6-mtu/
If you’re using SLAAC for auto IP assignment, then the resulting EUI-64-based address would be essentially static, based on the premise that your MAC address and local subnet prefix don’t change. Privacy extensions night get in the way, as well as Android’s randomized MAC feature, but those are adjustable.
Concrete example of threat modeling: if someone found out I was using Signal, for any reason at all, would that cause problems for me?
If yes, then Signal is not a good option. If no, then Signal may be appropriate. Why? Because in their documentation, they explicitly state that while messages are confidential, the fact that you’re using Signal cannot be hidden, and so they don’t make that guarantee.
Tbf, can’t the other party mess it up with signal too?
Yes, but this is where threat modeling comes into play. Grossly simplified, developing a threat model means to assess what sort of attackers you reasonably expect to make an attempt on you. For some people, their greatest concern is their conservative parents finding out that they’re on birth control. For others, they might be a journalist trying to maintain confidentiality of an informant from a rogue sheriff’s department in rural America. Yet others face the risk of a nation-state’s intelligence service trying to find their location while in exile.
For each of these users, they have different potential attackers. And Signal is well suited for the first two, and only alright against the third. After all, if the CIA or Mossad is following someone around IRL, there are other ways to crack their communications.
What Signal specifically offers is confidentiality in transit, meaning that all ISPs, WiFi networks, CDNs, VPNs, script skiddies with Wireshark, and network admins in the path of a Signal convo cannot see the contents of those messages.
Can the messages be captured at the endpoints? Yes! Someone could be standing right behind you, taking photos of your screen. Can the size or metadata of each message reveal the type of message (eg text, photo, video)? Yes, but that’s akin to feeling the shape of an envelope. Only through additional context can the contents be known (eg a parcel in the shape of a guitar case).
Signal also benefits from the network effect, because someone trying to get away from an abusive SO has plausible deniability if they download Signal on their phone (“all my friends are on Signal” or “the doctor said it’s more secure than email”). Or a whistleblower can send a message to a journalist that included their Signal username in a printed newspaper. The best place to hide a tree is in a forest. We protect us.
My main issue for signal is (mostly iPhone users) download it “just for protests” (ffs) and then delete it, but don’t relinquish their acct, so when I text them using signal it dies in limbo as they either deleted the app or never check it and don’t allow notifs
Alas, this is an issue with all messaging apps, if people delete the app without closing their account. I’m not sure if there’s anything Signal can do about this, but the base guarantees still hold: either the message is securely delivered to their app, or it never gets seen. But the confidentiality should always be maintained.
I’m glossing over a lot of cryptographic guarantees, but for one-to-one or small-group private messaging, Signal is the best mainstream app at the moment. For secure group messaging, like organizing hundreds of people for a protest, that is still up for grabs, because even if an app was 100% secure, any one of those persons can leak the message to an attacker. More participants means more potential for leaks.
When I see E2EE and XMPP mentioned, I think of this blog post by Soatok, outlining some very odd cryptographic choices in XMPP + OMEMO: https://soatok.blog/2024/08/04/against-xmppomemo/
I would very much like to see a richer playing field than just Signal for private messaging, but it’s a tough nut to crack. For exactly which aspect that turns me away from XMPP for E2EE, I think this nails it down:
you only need check whether OMEMO is on by default (it isn’t), or whether OMEMO can be turned off even if your client supports it (it can).
When the competition is Signal, these sorts of details matter a lot.
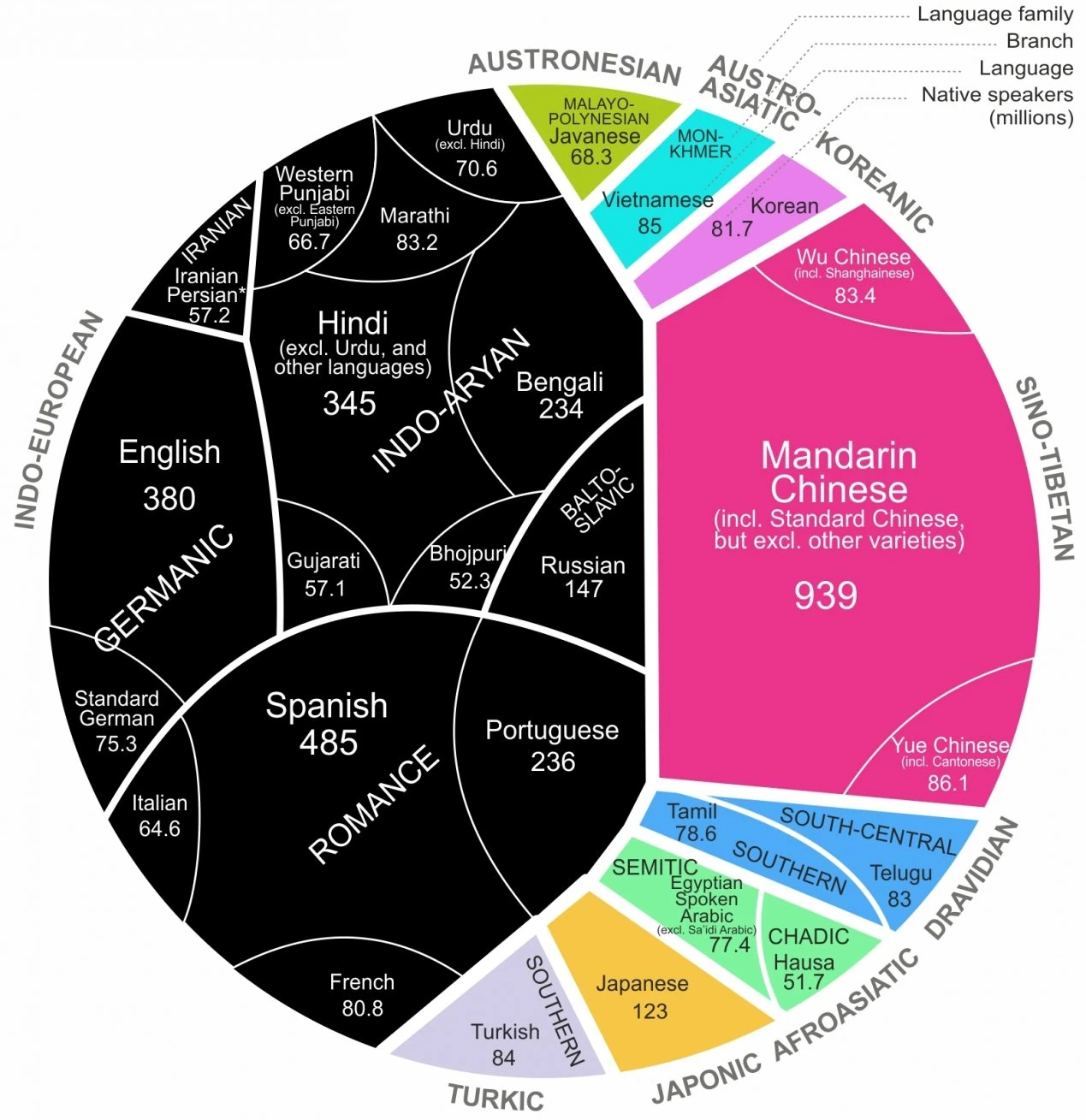
I can accept the premise that LLMs are being used to write Commons speeches – MPs are also people, I’m told – but these graphs suggest that LLMs are overusing certain stock phrases which have existed in the business world and apparently in Commons speeches since at least 2007.
What puzzles me is why LLMs are more prone to using these particular phrases. Does this happen for all users of LLMs, or only when British MPs in particular are requesting a speech?
I’d be interested to know if the same trend for the same phrases can be found in the Canadian House of Commons, since although they also follow much of the same procedures, North American English should skew the frequencies of certain words. So if the same trend can be found, then that suggests that the common LLMs do lean towards certain phrases. But if the trend is not statistically significant in Canada, then perhaps British MPs issue different prompts than their Canadian counterparts.
What I’m saying is that I rise today to highlight additional avenues of intrigue, as MPs and citizens alike are navigating a world where AI supposedly streamlines daily activities. That certain trends may or may not exist underscores the gravity of this seemingly bustling industry that we call AI.
[just to be clear, that last paragraph is entirely in jest]
Let me make sure I understand everything correctly. You have an OpenWRT router which terminates a Wireguard tunnel, which your phone will connect to from somewhere on the Internet. When the Wireguard tunnel lands within the router in the new subnet 192.168.2 0/24, you have iptable rules that will:
So far, this seems alright. But where does the service run? Is it on your LAN subnet or the isolated 192.168.2.0/24 subnet? The diagram you included suggests that the service runs on an existing machine on your LAN, so that would imply that the router must also do address translation from the isolated subnet to your LAN subnet.
That’s doable, but ideally the service would be homed onto the isolated subnet. But perhaps I misunderstood part of the configuration.

im not much of a writer, im sure its more clear from AI than if i did it myself
Please understand this in the kindest possible way: if you were not willing to write documentation yourself, why should I want to want review it? I too could use an AI/LLM to distill documentation rather than posting this comment but I choose not to, because I believe that open discussion is a central tenant of open-source software. Even if you are not great at writing in technical English, any attempt at all will be more germane to your intentions and objectives than what an LLM generate. You would have had to first describe your intentions and objectives to the LLM anyway. Might as well get real-life practice at writing.
It’s not that AI and LLMs can’t find their way into the software development process, but the question is to what end: using an AI system to give the appearance of a fully-flushed out project when it isn’t, that is deceitful. Using an AI system to learn, develop, and revise the codebase, to the point that you yourself can adequately teach someone else how it works, that is divine.
With that out of the way, we can talk about the high-level merits of your approach.
how the authentication works: https://positive-intentions.com/docs/research/authentication
What is the lifetime of each user’s public/private keypair? What is the lifetime of the symmetric key shared between two communicating users? The former is important because people can and do lose their private key, or have a need to intentionally destroy the key. In such instance, does the browser app explicitly invalidate a key and inform the counterparty? Or do keys silently disappear and also take the message history with it?
The latter is important because the longer a symmetric key is used, the more ciphertext that a malicious actor can store-and-decrypt later in time, possibly in the future when quantum computers can break today’s encryption. More pressing, though, is that a leak of the symmetric key means all prior and future messages are revealed, until the symmetric key is rotated.
how security works: https://positive-intentions.com/blog/security-privacy-authentication
I take substantial notice whenever a promise of “true privacy” is made, because it either delivers a very strange definition of privacy, or relies upon the reader to supply their own definition of what privacy means to them. When privacy is on offer, I’m always inclined to ask: privacy from whom? From network taps? From other apps running in the same browser?
This document pays only lip service to some sort of privacy notion, but not in any concrete terms. Instead, it spends a whole section on attempting to solve secure key exchange, but simply boils down to “user validates the hash they received through a secure medium”. If a secure medium existed, then secure key exchange would already be solved. If there isn’t one, using an “a priori” hash of the expected key is still vulnerable to hash attacks.
this is my sideproject and im trying to get it off the ground
I applaud you for undertaking an interesting project, but you also have to be aware that many others have also tried their hand at secure messaging, with more fails than successes. The blog posts of Soatok show us the fails within just the basic cryptography, and that doesn’t even get to some of the privacy issues that exist separately. For example, until Signal added support for username, it was mandatory to reveal one’s phone number to bootstrap the user’s identity. That has since been fixed, but they go into detail about why it wasn’t easy to arrive at the present solution.
am i a cryptographer yet?
I recall a recent post I saw on Mastodon, where someone who was implementing a cryptographic library made sure to clarify that they were a “cryptography engineer” and not a cryptographer, because they themselves have to consult with a cryptography regarding how the implementation would work. That is to say, they recognized that although they are writing the code which implements a cryptographic algorithm, the guarantees comes from the algorithm itself, which are understood by and discussed amongst cryptographers. Sometimes nicely, and other times necessarily very bluntly. Those examples come from this blog post.
I myself am definitely not a cryptographer. But I can reference the distilled works of crypgraphers, such as from this 1999 post which still finds relevancy today:
The point here is that, like medicine, cryptography is a science. It has a body of knowledge, and researchers are constantly improving that body of knowledge: designing new security methods, breaking existing security methods, building theoretical foundations, etc. Someone who obviously does not speak the language of cryptography is not conversant with the literature, and is much less likely to have invented something good. It’s as if your doctor started talking about “energy waves and healing vibrations.” You’d worry.
I wish you the very best with this endeavor, but also caution as the space is vast and the pitfalls are manifold.
Aiming to create the worlds most secure messaging app
For anyone else that was looking for it, this is the link to the threat model: https://positive-intentions.com/docs/research/threat-model/
That said, it seems quite thin on hard details, such as how identities (ie usernames) are managed – eg are they unique? How can users cross-check an online identity to a real person? Fingerprints? QR codes? SHA256 hashes? – and whether they are considered publicly-exchangeable. Plus how users are bootstrapped so they can find each other.
While a threat model is the minimum to even beginning an assessment of anything that utters the word “security”, I do have to ask:
This doesn’t answer OP’s question, but is more of a PSA for anyone that seeks to self-host the backend of an E2EE messaging app: only proceed if you’re willing and able to upkeep your end of the bargain to your users. In the case of Signal, the server cannot decrypt messages when they’re relayed. But this doesn’t mean we can totally ignore where the server is physically located, nor how users connect to it.
As Soatok rightly wrote, the legal jurisdiction of the Signal servers is almost entirely irrelevant when the security model is premised on cryptographic keys that only the end devices have. But also:
They [attackers] can surely learn metadata (message length, if padding isn’t used; time of transmission; sender/recipients). Metadata resistance isn’t a goal of any of the mainstream private messaging solutions, and generally builds atop the Tor network. This is why a threat model is important to the previous section.
So if you’re going to be self-hosting from a country where superinjunctions exist or the right against unreasonable searches is being eroded, consider that well before an agent with a wiretap warrant demands that you attach a logger for “suspicious” IP addresses.
If you do host your Signal server and it’s only accessible through Tor, this is certainly an improvement. But still, you must adequately inform your users about what they’re getting into, because even Tor is not fully resistant to deanonymization, and then by the very nature of using a non-standard Signal server, your users would be under immediate suspicion and subject to IRL side-channel attacks.
I don’t disagree with the idea of wanting to self-host something which is presently centralized. But also recognize that the network effect with Signal is the same as with Tor: more people using it for mundane, everyday purposes provides “herd immunity” to the most vulnerable users. Best place to hide a tree is in a forest, after all.
If you do proceed, don’t oversell what you cannot provide, and make sure your users are fully abreast of this arrangement and they fully consent. This is not targeted at OP, but anyone that hasn’t considered the things above needs to pause before proceeding.
I mean, at the USA average price of electricity of $0.13 per kWh, then for a halving of 70 Watts, it’s about 11 cents per day, or $40 per year. But at the California average price of $0.35, then the savings is 29 cents per day, or $107 per year.
That’s not small money, especially if it’s free to make these gains by ripping out unneeded functionality. But the point is taken that it’ll be hard to find savings from older hardware, which simply didn’t prioritize energy efficiency.
A Nintendo Wii would also work, as exemplified by this blog running on a NetBSD Wii.
But in all seriousness, the original comment has a point: using a mobile phone as a server is possible but also wastes a lot of the included hardware, like the cellular baseband, the touchscreen, and the voice and Bluetooth capabilities. Selling the phones and using the proceeds to purchase a used NUC or an SFF PC would give you more avenues to expand, in addition to just being plain easier to set up, since it would have USB ports, to name a few luxuries.
IANAL either, but I’m vaguely familiar that this realm of USA law is known as “choice of law” provisions and the applicability of “click wrap” contracts, and it’s a thorny issue in the digital age. Essentially, the problem is whether Meta can be made reasonably aware that a ToS exists for a given web server. Unlike a “NO TRESPASSING” sign posted on a gate, or a sticker on the packaging of a physical copy of Microsoft Word 97 that says “opening this package constitutes agreement to the EULA, at this URL…”, it can be argued that unless the ToS is made so blitheringly obvious to a web scraper, it might not pass muster.
To be clear, this isn’t a problem for normal web users, because the ToS link will very easily appear at the bottom of the page, when rendered in a standard web browser. The issue is whether scrapers – including AI scrapers but also bot-crawlers and even plain ol Curl – would see the notice of the ToS. There is no convention – either de facto or in law – about where or what format a ToS has to be. And it would be problematic to say that all scrapers need to thoroughly search a website for a “legal.txt”, because such a file might be somewhere non-obvious and because it exacerbates the whole “scrap servers until they collapse” issue.
So already, getting a ToS to bind Meta – or any other high-volume scraper – is an upward battle. Hence why I suggested a remedy rooted in common law, premised on the idea that actively causing expenses for the server owner is actionable, even without a ToS.
That said, I do want to point out one other detail about choice-of-law: normally if a contract specifies the venue for disputes, that will be honored. Example: the courts of Santa Clara County in California. But supposing the instance owner lives in Montreal and specifies the venue as the Court of Quebec, and if the issue with binding Meta to the ToS was solved, then there’s the challenge of actually targeting Meta. As a USA domiciled corporation, they’re not automatically within the jurisdiction that the Quebec courts can reach. If there’s a Canadian subsidiary, that might be a valid target. But if not, the Quebec courts wouldn’t be able to compel Meta’s lawyers to even show up, let alone rule in favor of the instance owner. And then there’s the whole aspect of getting an American court to ratify a judgement issued by an overseas court. It’s doable, but it’s so much harder than specifying a venue within the USA.
But again, that’s problematic if the instance isn’t located within the USA, because then the owner must travel to the USA for their court dates. And I can’t really recommend that anyone travel to the USA except for only the most critical or dire of situations.
From my limited experience with PoE switches, how much power being drawn in relation to how much the switch can supply has a notable impact on efficiency. Specifically, when only one or two ports on a 48-port switch are delivering PoE, the increased AC power drawn from the wall is disproportionately high. Hence, any setup where you’re using more of the PoE switch’s potential power tends to increase overall efficiency.
My guess is that it has to do with efficiency curves that are only reasonable when heavily loaded for enterprise customers. In any case, if either of those two candidate switches meet your needs today and with some breathing room, both should be fine. I would tend to lean towards Netgear before TP-Link though, out of personal preference.
The cynicism surrounding the USA court system is not without cause, but the suggestion to not even bother trying has always rubbed me the wrong way. Firstly, on philosophical grounds, it’s defeatism and on-par with appeasement. But secondly, average Americans can and have prevailed when up against a multinational company.
The one which often comes to mind is the case of a Philadelphia man winning a default judgement against Wells Fargo and was on the cusp of having the local sheriff auction off a branch’s furniture, until they all settled the matter. The man in question wrote about his experience here: https://lawsintexas.com/this-is-how-my-qwr-foreclosed-wells-fargo/
As for how to use Meta, the average Joe need not hire a major law firm, but can choose to pursue a limited suit in small claims court. For Meta, which is headquartered in Silicon Valley in California, the Superior Court in Santa Clara County would be the venue. Drawbacks include: having to get to Silicon Valley for court dates, and a total claims limit of $12.5k.
But on the flip side, the small claims court does not allow lawyers to argue the case before the judge, meaning it’s basically you and Meta’s representative. That representative might still have legal training, but it won’t be a situation like in the 1997 film The Rainmaker where it’s one solo lawyer versus a whole team of lawyers.
There’s also fewer avenues for Meta to inflate costs, such as attempting to pull the case into federal court: diversity jurisdiction isn’t available unless a claim is over $75k. But they can create difficulties through the discovery process, and other pre-trial activities.
Do I think this is viable? Possibly, but it’ll still take a fair amount of effort to have a lawyer work the case prior to trial, even if that lawyer can’t actually do the talking in front of the judge. Easily 5 digit territory to pay your lawyer. But again, this is balanced by Meta having to deal with the nuisance of having someone on their side also put in a similar amount of effort. And when the max cap for small claims is $12.5k, Meta also has enough money to just pay up and then steer their AI scrapers away from your server, saving everyone the bother. See “nuisance value lawsuits”. Also, spiteful lawsuits are a thing.
After all, it’s not like everyone is going to sue Meta in small claims court, right? Right?
In the somewhat-distant past, “trespass to chattels” is a type of lawsuit in Anglo-American law that could be raised in response to the abuse of a publicly-accessible computer system, originally meant as a remedy for the diminishment of someone’s else’s property (eg milking their cow). How the modern case law is understood, it allows the owner of a system (eg a Fediverse instance) to recover money due to a tortfeasor’s (eg Meta) conduct that interferes with the normal function of the system. The bar had been raised since the 80s, requiring direct impact to the system, not just that someone accessed the system without explicit authorization. Even outright malice does not suffice, since the test is whether the system was degraded in some way.
A run-of-the-mill scraper querying once daily wouldn’t meet the test, and something as minimal as an ICMP ping every second wouldn’t meet the test. But AI scraping to the tune of hundreds of queries per day, adding up to double digit percentage points of server bandwidth for a small Fediverse instance, that might.
That some instance operators have to consider adding more vCPUs or RAM, or operators that successfully applied blockers like Anubis, in response to AI scraping underscores how harmful – and thus potentially legally actionable – those actions are, suggesting a decent chance such a lawsuit could be successful.
https://github.com/Overv/vramfs
Oh, it’s a user space (FUSE) driver. I was rather hoping it was an out-of-tree Linux kernel driver, since using FUSE will: 1) always pass back to userspace, which costs performance, and 2) destroys any possibility of DMA-enabled memory operations (DPDK is a possible exception). I suppose if the only objective was to store files in VRAM, this does technically meet that, but it’s leaving quite a lot on the table, IMO.
If this were a kernel module, the filesystem performance would presumably improve, limited by how the VRAM is exposed by OpenCL (ie very fast if it’s just all mapped into PCIe). And if it was basically offering VRAM as PCIe memory, then this potentially means the VRAM can be used for certain RAM niche cases, like hugepages: some applications need large quantities of memory, plus a guarantee that it won’t be evicted from RAM, and whose physical addresses can be resolved from userspace (eg DPDK, high-performance compute). If such a driver could offer special hugepages which are backed by VRAM, then those application could benefit.
And at that point, on systems where the PCIe address space is unified with the system address space (eg x86), then it’s entirely plausible to use VRAM as if it were hot-insertable memory, because both RAM and VRAM would occupy known regions within the system memory address space, and the existing MMU would control which processes can access what parts of PCIe-mapped-VRAM.
Is it worth re-engineering the Linux kernel memory subsystem to support RAM over PCIe? Uh, who knows. Though I’ve always like the thought of DDR on PCIe cards. All technologies are doomed to reinvent PCIe, I think, said someone from Level1Techs.